Should you chase an agent-readiness score? From Level 1 to Agent-Native
TL;DR — isitagentready.com scored our site 29, Level 1. Instead of filling the scorecard, we picked only what has substance: Content Signals, markdown negotiation, Agent Skills, plus a real MCP server and DNS-AID with DNSSEC. That took us to 71, Level 5 "Agent-Native". The 4 items we skipped were skipped for a reason: metadata for a service that doesn't exist is a lie told to agents.
Cloudflare launched isitagentready.com during Agents Week: 20 checks that score how ready a site is for AI agents. The framing sticks. "The web learned to speak to browsers, then to search engines. Now it must learn to speak to AI agents."1 We scanned our site and the result wasn't pretty: 29 points, Level 1 "Basic Web Presence", with ten items missing.
Scores move people, as Lighthouse proved. So before filling anything in, we asked a prior question: what does this score actually measure?
The score blends three different things
Agent-readiness tools measure not one axis but three distinct dimensions.2
| Dimension | Question | Typical checks |
|---|---|---|
| Content accessibility | Can an agent read the page? | Markdown views, llms.txt, SSR |
| Protocol adoption | Did you implement emerging standards? | MCP Server Card, API Catalog, OAuth discovery |
| Real-traffic alignment | Do agents actually use those standards? | .well-known probes in server logs |
The dimensions don't compensate for each other. Dachary Carey, author of the AFDocs spec, proved it by scanning her own site with both tools: a site that coding agents read perfectly (AFDocs 100/100) scored 33 on Cloudflare's scale, "Level 1: Basic Web Presence."2
The traffic evidence stings more. Among the standards Cloudflare scores, MCP Server Card and API Catalog have fewer than 15 adopters combined across the top 200k domains, and server logs from an agent-heavy site showed essentially zero requests probing those .well-known endpoints.2 The point about robots.txt and sitemaps also holds: they serve crawlers like GPTBot, not coding agents. A large share of the score measures readiness for a future that hasn't arrived.
That doesn't make the score meaningless. Per Cloudflare's Radar dataset, 78% of the top 200k domains have robots.txt, but only 4% publish Content Signals and 3.9% support markdown negotiation.1 The standards are early, and adoption trends are a usable signal for when to invest in the protocol layer.
Our rule: substance only
Reviewing the 10 items, we set one principle. Never publish metadata for a service that doesn't exist. Posting OAuth discovery documents with no protected API, or an MCP card with no server, raises the score while feeding agents a false signal.
| Verdict | Item | Reasoning |
|---|---|---|
| Adopt | Content Signals | A few robots.txt lines; AI crawlers have started parsing it |
| Adopt | Markdown for Agents | The content-accessibility layer, the one with proven effect |
| Adopt | Agent Skills index | Real skills: requesting a consultation, reading content |
| Adopt | MCP Server Card + API Catalog | By building the actual server to back them |
| Adopt | DNS-AID + DNSSEC | The MCP endpoint gives the records something to point at |
| Skip | OAuth discovery ×2, auth.md | No service that requires authentication |
| Skip | WebMCP | Chrome Early Preview stage; the standard hasn't settled |
Half filled, nearly half deliberately left empty. But we're an AX consulting firm. To talk to clients about agent readiness, our own site has to be the proof. So instead of waiting for the protocol layer to show up in traffic, we pulled it forward by building the substance first.
What we actually built
An agent meets a site at three layers: it discovers, it reads, it acts.
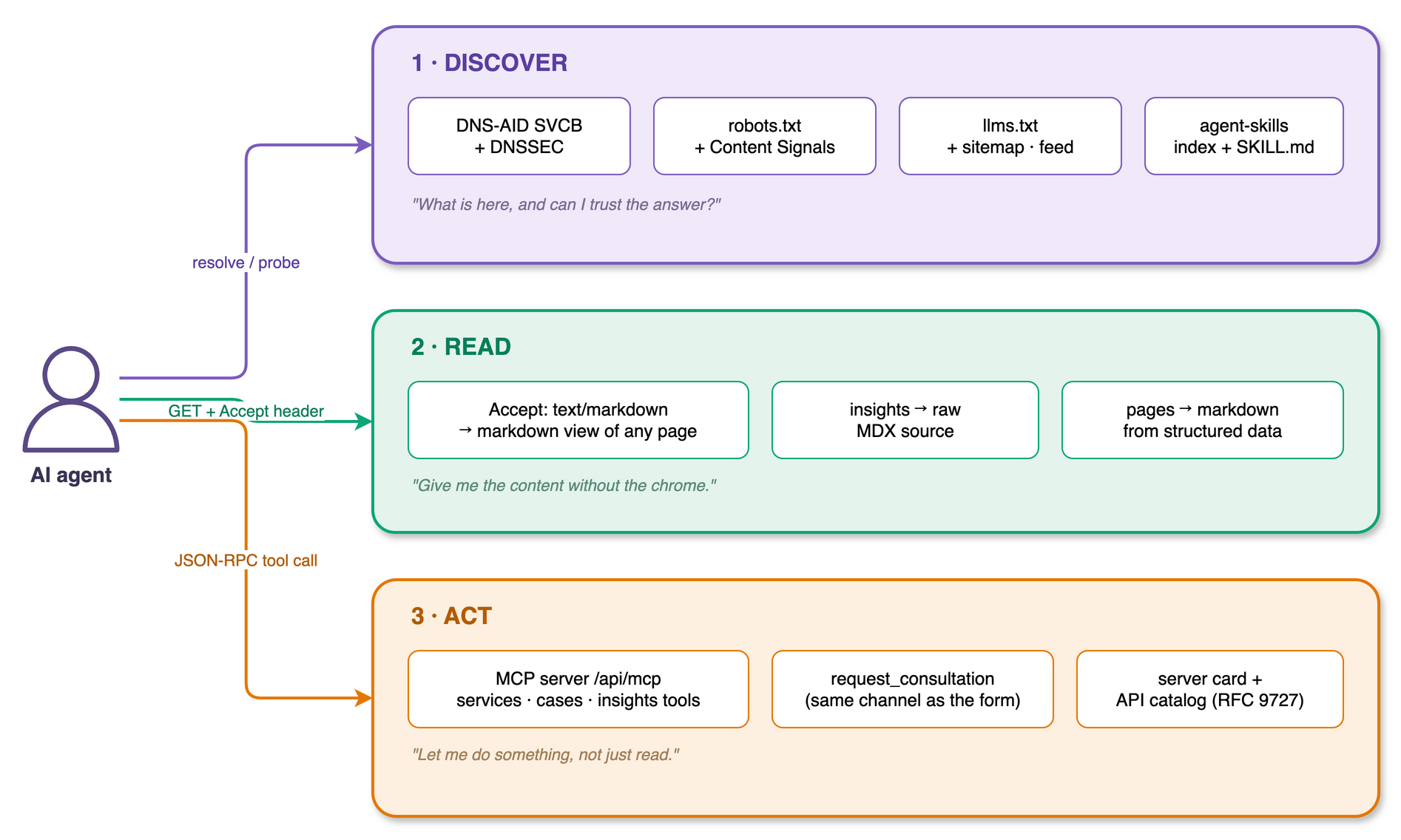
Read: markdown negotiation
Send Accept: text/markdown to any URL and you get markdown instead of HTML. Browsers never send that header, so the human experience is untouched. Cloudflare's own benchmark puts the token savings of markdown negotiation at up to 80% (self-measured, so treat the number as directional).1
The implementation came down to one middleware branch and one route. Insights articles are authored in MDX, so they ship essentially as source. Every other page skips HTML conversion entirely: we assemble markdown from the same structured data that renders the page. One source, two views, nothing to drift.
Discover: Content Signals and a skills index
We declared three values in robots.txt.
User-Agent: *
Content-Signal: search=yes, ai-input=yes, ai-train=yes
Allow: /
ai-train=yes is a policy call. A publisher protecting content revenue might rightly say no. For a marketing site, future models training on our content is brand exposure. This trade-off has a different answer per site.
Under /.well-known/agent-skills/ we published a skills index with three entries: how to request a consultation, how to read our content as markdown, and how to use the MCP server. Each SKILL.md's sha256 digest is computed at build time, so the index can never drift from the bodies.
Act: a real MCP server
Publishing an MCP Server Card requires an MCP server. So we built one. With mcp-handler, a single Next.js route runs a Streamable HTTP server carrying seven tools: six content tools for services, case studies, and insights, plus request_consultation.
The consultation tool required no new backend. It calls the same server action the web form uses. One set of validation, one email path, and a consultation filed by an agent lands in the same channel as one typed by a person. Building a separate system for agents would have doubled the maintenance for nothing.
Trust: DNS-AID and DNSSEC
DNS-AID is an IETF draft for advertising agent endpoints through DNS.3 With the MCP server live, the records finally had something to point at. Two SVCB records went into Route 53.
_index._agents.801pla.net. 3600 IN SVCB 1 801pla.net. alpn="h2" port="443"
_mcp._agents.801pla.net. 3600 IN SVCB 1 801pla.net. alpn="h2" port="443"
The draft asks for DNSSEC so validating resolvers return authenticated data. Our domain is registered with Route 53 Domains, so everything from the KMS key through the KSK, zone signing, and the registrar DS record happened in one account. When the zone and the registrar live in the same place, the classic cause of DNSSEC outages, drift between the two, is structurally gone.
One lesson from the cutover: right after the DS record reached the parent zone, Cloudflare's resolver briefly returned SERVFAIL. That's the transition window where pre-signing cached answers collide with the new chain of trust; signing the zone first and publishing DS second keeps the window small. And if you ever roll back, the order reverses: remove the DS first, wait for propagation, then stop signing. Get it wrong and the whole domain stops resolving.
The rescan came back 71 points, Level 5 "Agent-Native". Discoverability, Content, and Bot Access Control all hit 100, and every remaining gap in the Discovery category is one we chose to leave (the OAuth family and WebMCP).
Does any of this help SEO?
Only partially. The content-accessibility layer (markdown views, allowing AI crawlers) feeds generative-search citations, but the protocol layer that dominates the score is irrelevant to search visibility. Generative engines don't consult MCP cards or OAuth metadata when composing answers.
Two cautions. A study across 300k domains found no statistical correlation between having llms.txt and being cited by LLMs,4 and clamping down on AI bots via Content Signals can reduce citations, trading AI visibility for content control. If search and citations are the goal, skip the score and execute only the overlapping layer.
The verdict
Read an agent-readiness score as a roadmap signal, not a report card. The content-accessibility layer pays off today, so do it first. The protocol layer, as a rule, is worth implementing when your server logs show agents probing for it.2 We pulled that moment forward for the proof value, but even then the order held: build the substance first, publish the metadata second.
There's also a better test than any score: hand your site to an actual agent. Thirty minutes with a coding agent like Claude Code reveals things no scanner will tell you.
If you're weighing the direction of an AI transformation, agent readiness included, start with AX Consulting. If you need a team to build this kind of infrastructure, see Cloud & Infrastructure.
References
Footnotes
-
André Jesus, Vance Morrison (Cloudflare), "Introducing the Agent Readiness score. Is your site agent-ready?" (2026-04-17). Includes the Radar adoption dataset and the token-savings benchmark (self-measured). https://blog.cloudflare.com/agent-readiness/ ↩ ↩2 ↩3
-
Dachary Carey, "What an Agent Score Can Tell You" (2026-04-18). The AFDocs 100/100 vs Cloudflare 33/100 experiment and
.well-knownreal-traffic log analysis. https://dacharycarey.com/2026/04/18/what-agent-score-can-tell-you/ ↩ ↩2 ↩3 ↩4 -
IETF Internet-Draft, "DNS for AI Discovery (DNS-AID)". Agent endpoint discovery via SVCB/HTTPS records. https://datatracker.ietf.org/doc/draft-mozleywilliams-dnsop-dnsaid/ ↩
-
A 300k-domain study on the correlation between llms.txt and LLM citations. Vendor claims and large-scale measurements conflict, so we treat this with low confidence. ↩